0
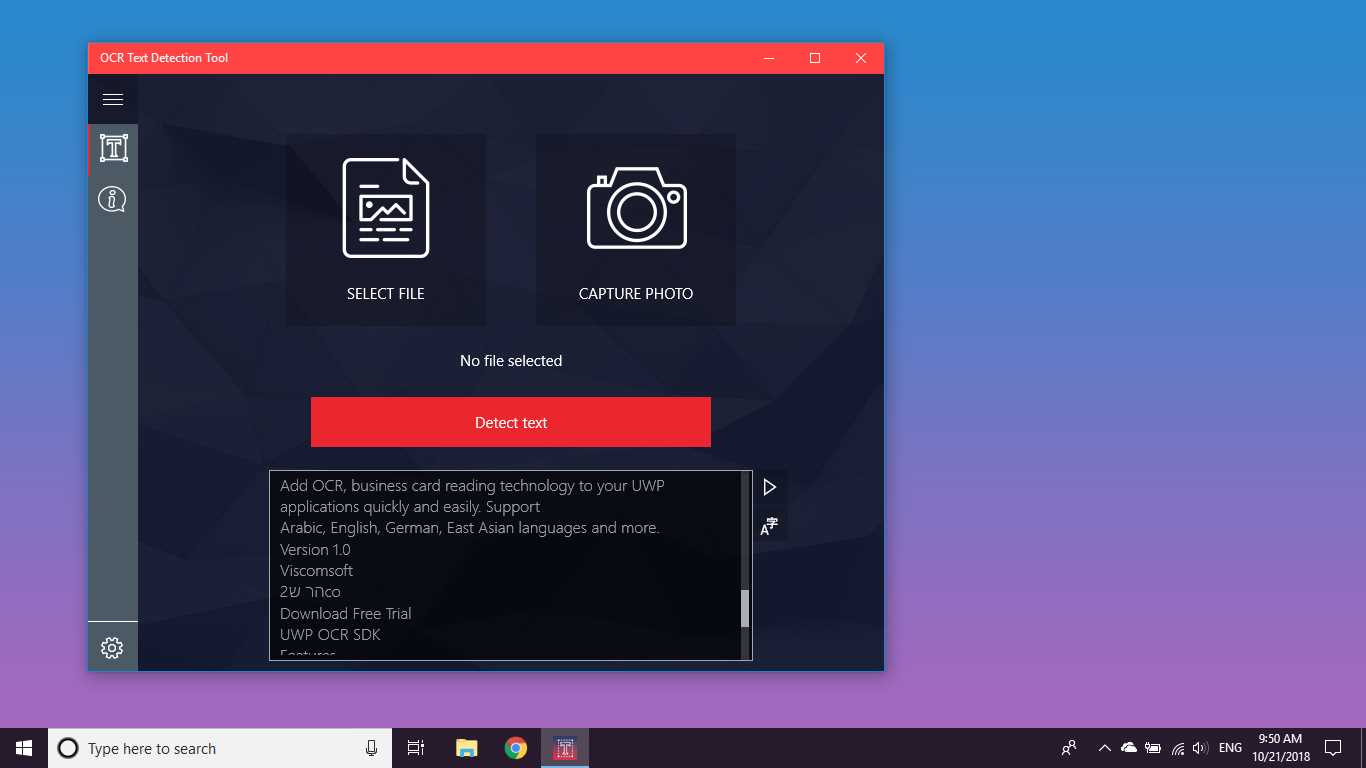
OCR Text Detection Tool
Proporciona detección de texto precisa y rápida de cualquier archivo de imagen descargado de su dispositivo o tomado con una instantánea.También admite la detección textual de un PDF y la detección de escritura a mano basada en texto y traducción de texto en 114 idiomas diferentes.
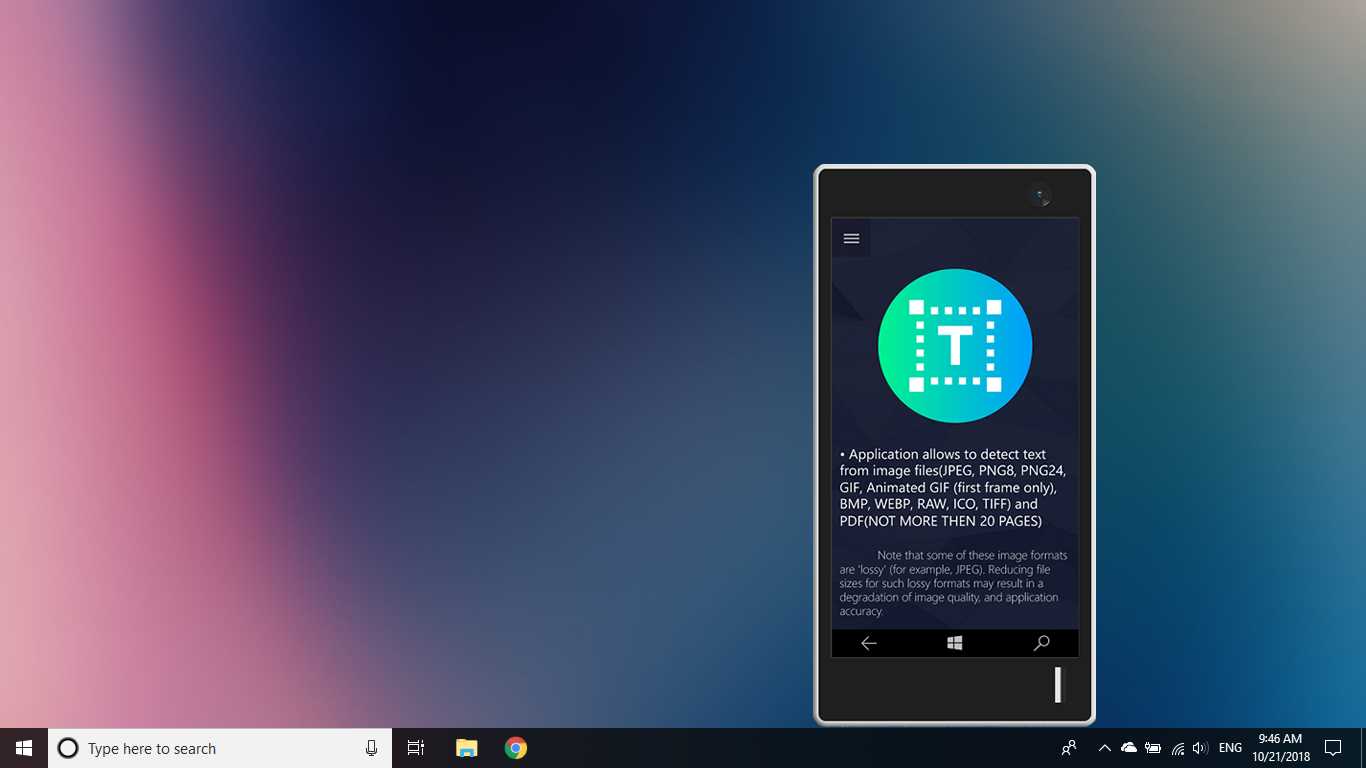
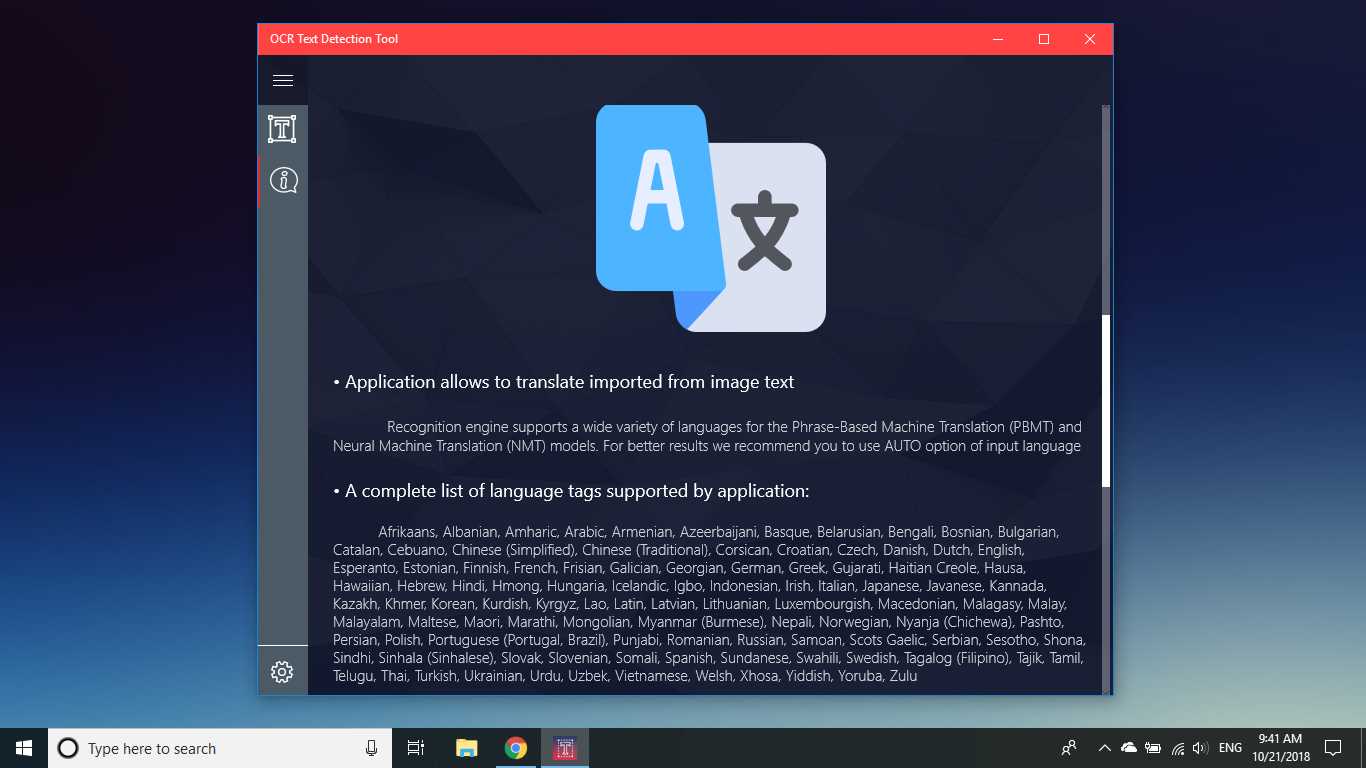
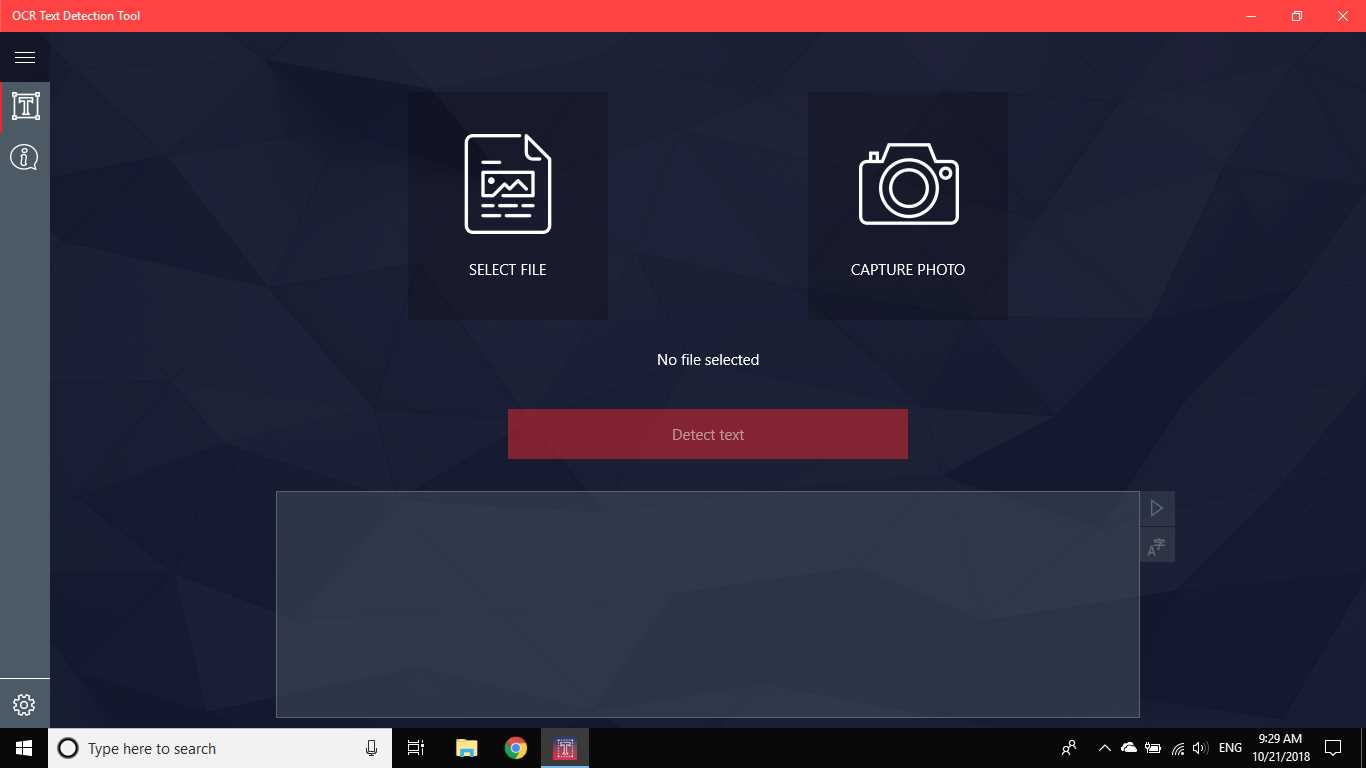
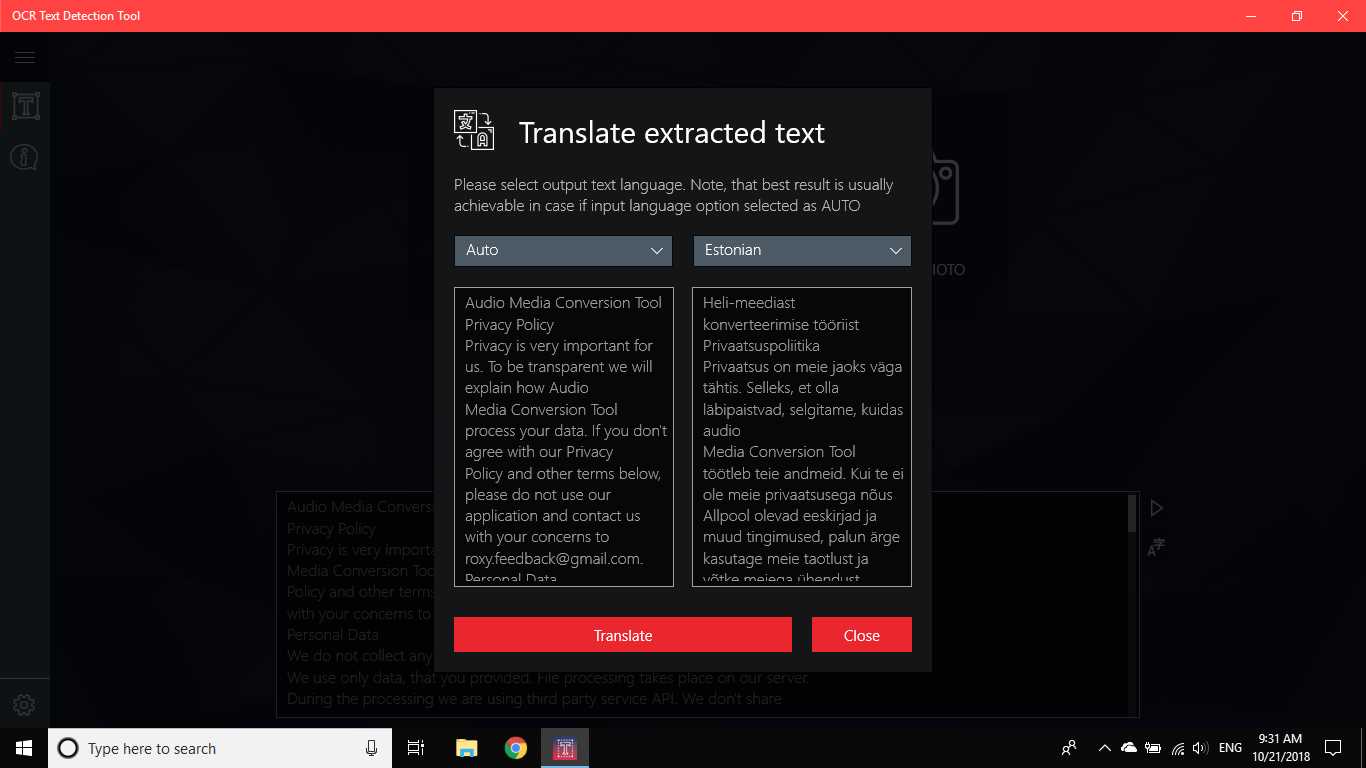
La herramienta de detección de texto OCR proporciona una detección de texto precisa y rápida de cualquier archivo de imagen descargado de su dispositivo o tomado con una instantánea.También admite la detección textual de un documento PDF (actualmente no más de 20 páginas, pero estamos trabajando para expandir la funcionalidad).La aplicación también admite la detección de escritura a mano basada en texto y la traducción de texto en 114 idiomas diferentes.El diseño amigable, claro y conveniente hace que trabajar con la aplicación sea fácil y comprensible.* Formatos disponibles: JPEG, PNG8, PNG24, GIF, GIF animado (solo primer fotograma), BMP, WEBP, RAW, ICO, TIFF, PDF (actualmente no más de 20 páginas, pero estamos trabajando para ampliar la funcionalidad) * TextoLa función de reconocimiento puede detectar una amplia variedad de idiomas y puede detectar múltiples idiomas dentro de una sola imagen: afrikaans (af), árabe (ar), asamés (as), azerbaiyano (az), bielorruso (be), bengalí (bn), Búlgaro (bg), catalán (ca), chino (zh *), croata (hr), checo (cs), danés (da), holandés (nl), inglés (en), estonio (et), filipino (filo tl), finlandés (fi), francés (fr), alemán (de), griego (el), hebreo (he o iw), hindi (hi), húngaro (hu), islandés (is), indonesio (id), Italiano (it), japonés (ja), kazajo (kk), coreano (ko), kirguiso (ky), letón (lv), lituano (lt), macedonio (mk), marathi (mr), mongol (mn), Nepalí (ne), noruego (no), pashtu (ps), persa (fa), polaco (pl), portugués (pt), rumano (ro), ruso (ru), sánscrito (sa), serbio (sr), Eslovaco (sk), esloveno (sl), español (es), sueco (sv), tamil (ta), tailandés (th), turco (tr), ucraniano (uk), urdu (ur), uzbeko (uz), vietnamita (vi) ¡Compruébalo, no tienes nada que perder!
Caracteristicas
Categorias
Alternativas a OCR Text Detection Tool para Linux
71
35
GImageReader
gImageReader es un simple front-end Gtk / Qt para el motor Tesseract OCR.Características: - Importe documentos PDF e imágenes desde disco, dispositivos de escaneo, portapapeles y capturas de pantalla
9
8
6
5
5
4