9
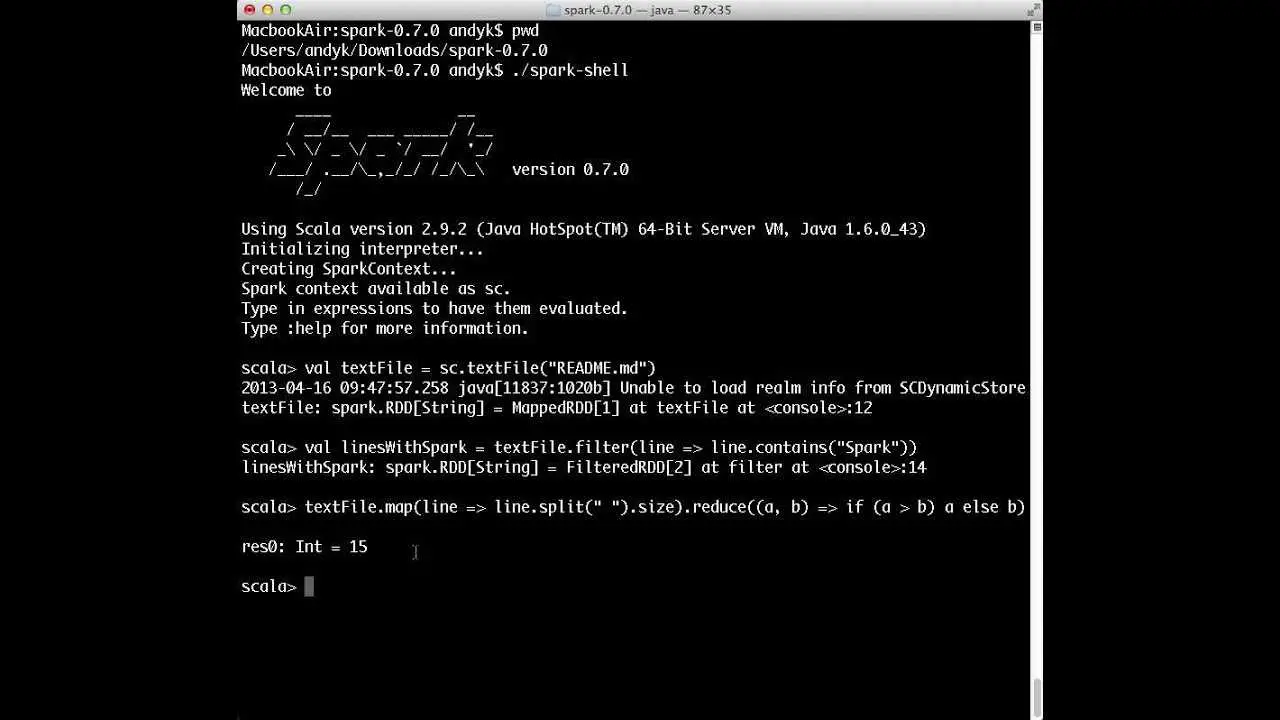
Apache Spark ™ es un motor rápido y general para el procesamiento de datos a gran escala.Speed Run programa hasta 100 veces más rápido que Hadoop MapReduce en la memoria, o 10 veces más rápido en el disco.Spark tiene un motor de ejecución de DAG avanzado que admite el flujo de datos cíclicos y la computación en memoria.
Sitio web:
http://spark.apache.orgCaracteristicas
Categorias
Alternativas a Apache Spark para Linux
18
Apache Hadoop
Apache Hadoop es un marco de software de código abierto que admite aplicaciones distribuidas de uso intensivo de datos con licencia bajo la licencia Apache v2.
1
Disco MapReduce
Disco es un marco ligero y de código abierto para la computación distribuida basada en el paradigma MapReduce y escrito en Python.